
Check our case study
Extending Architecture & Automation Capacity
SOFTWARE DEVELOPMENT SERVICES
Your roadmap.
Fully staffed.
Always moving.
We embed senior engineers into your team — so you hit deadlines, reduce overhead, and ship the software that grows your business.
Schedule A Call

Trusted by Product and Engineering Leaders at Global Companies
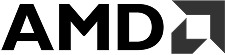
End-to-end software expertise,
with engineers who act like owners.
Custom software development
Design and build scalable web and mobile applications aligned to your business goals and technology stack.
Product, delivery, and QA
Product, design, and delivery expertise to build and scale software with speed, quality, and operational discipline.
Cloud and platform engineering
Modernize and scale cloud platforms with DevOps, reliability engineering, and enterprise-grade platform practices.
Data engineering & AI
Apply modern data platforms and AI to enable analytics, automation, and intelligent decision-making.
Enterprise business platforms
Modernize and optimize ERP, CRM, and enterprise workflow platforms to support complex business operations.
DX and commerce platforms
Develop and extend enterprise CMS and commerce platforms across modern digital ecosystems.
ABOUT PARALLELSTAFF
Nearshore talent. US standards.
Predictability by design.
We're a US-based company backed by top-tier nearshore engineering talent. That means faster procurement, shared quality standards, and a team that's accountable from day one.
Our engineers work your hours, communicate in English, and know how US product teams operate — so you get the speed and cost benefits of nearshore staff augmentation, without the trade-offs you've come to expect.

"Fast, professional communication and high-quality candidates have made ParallelStaff a valuable part of our strategy.”
DELIVERY MODELS
Scale your team on your terms.
Whether you need one engineer or a full team, there's a model built for you.

Staff augmentation
Best for: Teams needing 1-5 engineers to fill specific skill gaps fast.
- Senior engineers integrated into your team and workflows
- You retain full management control
- Scale up or down with zero long-term commitment
- Integrates into your existing tools and standups
Dedicated teams
Best for: Companies building a long-term engineering unit in LATAM.
- Full team assembled and managed end-to-end
- Consistent collaboration and team culture
- Ideal for product companies and SaaS platforms
- Covers full SDLC: design, dev, QA, DevOps
Software outsourcing
Best for: Startups and enterprises launching a new product or feature set.
- Project-scoped engagement with defined deliverables
- Senior talent with hands-on product experience
- Agile delivery with regular sprint reviews
- Full IP ownership transferred to your company
CASE STUDIES
See all Case Studies ->Proven across 130+ sectors.
See what we built for teams like yours.
See all Case Studies

Your next engineer could start in 2 weeks. Tell us what you need, we'll handle the rest.
OUR STANDARDS
The standards behind our delivery.
Our clients don't just need talent — they need certainty. Certainty that the engineers they bring on will perform, communicate, integrate, and deliver. That's why we built ParallelStaff around five non-negotiable standards that remove the guesswork and make every engagement predictable from day one.

01
People Standard
Only the top 5% of engineers, rigorously vetted for technical excellence and long-term performance.

02
Security Standard
ISO 27001-certified, US-based, and fully insured—protecting your data, IP, and AI initiatives.

03
Communication Standard
Cambridge English-based evaluations ensure fluent, client-ready communication from day one.

04
Project Continuity Standard
Low-attrition teams deliver continuity, retained knowledge, and predictable outcomes.

05
Delivery Standard
ITIL-aligned processes and clear SLAs ensure smooth collaboration and predictable outcomes.
Yes. We support your technology stack.
Our engineers work across modern and established technologies—integrating seamlessly with your existing systems and teams.
Enterprise Standards Are Our Baseline.
Our delivery model is backed by industry certifications, leading technology partnerships, and recognition from trusted institutions.
Delivery & Process Standards
Aligned with globally recognized delivery and security frameworks.
Structured service delivery and SLA governance

Information security and data protection controls
Client Trust & Market Validation.
Verified client reviews and third-party market research.

Inc. Power Partner for high-growth companies
Top-ranked service providers worldwide
Business & Industry Recognition
Independent validation of growth, leadership, and execution.
One of America’s fastest-growing private companies
Recognized technology leadership
Cloud & AI Partnerships
Certified expertise across leading cloud and AI platforms.
THREE DELIVERY MODELS, ONE DECISION
How do you want to work with us?
Each model gives you a different level of control, involvement, and speed. Pick what fits how your team operates.
Staff augmentation
Recommended
Dedicated teams
Software outsourcing
Scale teams as needed
Adjust headcount on demand
Integrated into your team
Devs join your workflows & standups
Dedicated full team provided
Pre-built squad delivered end-to-end
You retain management control
CTO directs priorities & sprints
Project management included
PM & delivery handled by vendor
Time to first developer
Speed of onboarding
Fast (days)
Medium 1-2 weeks
Medium 1-2 weeks
Full IP & code ownership
Clear client ownership of all output
Visibility into day-to-day work
Sprint access, standups, reporting
Our engagement
process. Clear.
Predictable. Proven.

STEP 1
Intro conversation
We get to know your team, your goals, and your engineering gaps. No commitment — just a quick conversation to see if we're a good fit to work together.
STEP 2
Discovery call
We go deeper into your needs, present our delivery models, and walk you through how we work. You'll have everything you need to make a confident decision.
STEP 3
Build your engineering capacity
We close your talent gap fast. We define the roles, team structure, present pre-vetted engineers for you to interview and select, handle all agreements, and get your expanded team live — on your timeline.
STEP 4
Ongoing performance and accountability
Your team delivers with consistency. We maintain performance oversight, run monthly business reviews, and hold biweekly syncs to keep velocity high and results measurable.
Frequently Asked Questions
We align on your objectives, team requirements, delivery expectations, timelines, and success criteria to determine the right engagement model.
Nearshore software development services give you better time zone alignment, faster communication, and smoother day-to-day collaboration than offshore outsourcing. For U.S. companies, this often means quicker decisions, fewer delays, and stronger delivery outcomes while still keeping costs competitive.
Staff augmentation adds skilled engineers to your existing team while you keep full control of delivery. A dedicated development team gives you an embedded team focused on your roadmap, while software outsourcing is ideal when you want a partner to take on a broader delivery role, including development, QA, and ongoing execution.
Yes. Many companies begin with staff augmentation to solve immediate capacity needs and then transition into a dedicated development team as the project grows. This gives you flexibility while keeping your software development strategy aligned with business goals.
Yes. A strong software development partner should be able to integrate with your in-house team, workflows, and tools without creating friction. This approach helps you move faster, close skill gaps, and maintain visibility across the entire software development process.
Timelines depend on the scope and engagement model, but nearshore software development teams can often get started much faster than traditional hiring. If speed is a priority, contact us, and we can discuss the fastest path to launching your project or scaling your team.
Yes. If your project is behind schedule, lacks quality, or fails to meet expectations, a software outsourcing partner can step in, assess the current state, and help stabilize delivery. This is often the fastest way to recover momentum without restarting from scratch.
Software development services can support a wide range of business needs, including custom web applications, SaaS platforms, mobile apps, internal business systems, cloud solutions, AI-driven tools, and software quality assurance initiatives. The right approach depends on your goals, technical environment, and growth plans.
Software development services are a strong fit if you need to accelerate delivery, access specialized talent, reduce hiring friction, or outsource execution to a trusted partner. If you’re evaluating options, contact us, and we'll help you determine whether staff augmentation, a dedicated team, or managed software outsourcing is the best fit for your goals.
Choose staff augmentation when you already have internal leadership, processes, and product direction in place, but need additional engineering capacity fast. If you need a partner to take more ownership over planning, development, QA, and delivery, managed software development services are usually the better option.
We scope every project based on your business goals, technical requirements, delivery timeline, and the level of support you need. Pricing depends on project complexity, team composition, and whether you need staff augmentation, a dedicated development team, or fully managed software development services. For a tailored estimate, contact us, and we'll help you define the right model for your budget and roadmap.
High-performing software development services rely on strong delivery processes, clear communication, and software quality assurance built into every stage of the project. That includes code reviews, structured QA, testing workflows, and close coordination between engineering and product teams to reduce risk and keep delivery on track.
Yes. Many companies need more than just development, they also need ongoing support, maintenance, updates, and performance improvements after launch. That’s why post-launch support is an important part of long-term success in software outsourcing.
Protecting your code, data, and intellectual property starts on day one with secure access controls, confidentiality agreements, and disciplined processes for handling sensitive information. We also follow ISO 27001-aligned security standards to support strong protection, compliance, and delivery accountability throughout the engagement
Managed software development services are typically priced based on scope, complexity, delivery model, and the expertise required across the team. If you need a more strategic partner to handle execution, QA, and delivery, contact us to discuss the best-fit solution and pricing structure for your business.
Software quality assurance is essential because it helps ensure your software is reliable, secure, and ready for real-world use. A strong software quality assurance process reduces bugs, improves performance, supports faster releases, and helps prevent costly issues after launch. For companies investing in custom software development, QA is not just a testing step; it is a critical part of delivering a better product and protecting long-term business value.

Powering Omni-Channel Growth for J.Crew
Read Case StudyStart with a conversation. We'll walk you through what working with us actually looks like.
Schedule a call
